Why SEO Doesn't Work: How to Check Page Rendering on a Website?
Author - Constantin Nacul
Virtually all modern websites are designed with the user in mind and the rendering capabilities of browsers. As a rule, browsers cope even with complex tasks without any problems.
But if we are talking about organic search, then all search engines rank web pages as HTML documents. And search bots, unlike modern browsers, have limited options. If you don't take care of how search engine crawlers see your pages, you can lose the race for the top positions in organic search.
How to check the rendering of the site and eliminate errors that interfere with the ranking - we will tell further.
What is page rendering in SEO?
Rendering is a term from web development. It refers to rendering the code of a web document into an interactive web page that you eventually see in your browsers. In fact, rendering is the process of fulfilling all the rules written in HTML code, JS scripts and CSS styles.
What happens in the browser when the document is displayed:
- The browser receives resources from the server (HTML code, CSS, JS, images).
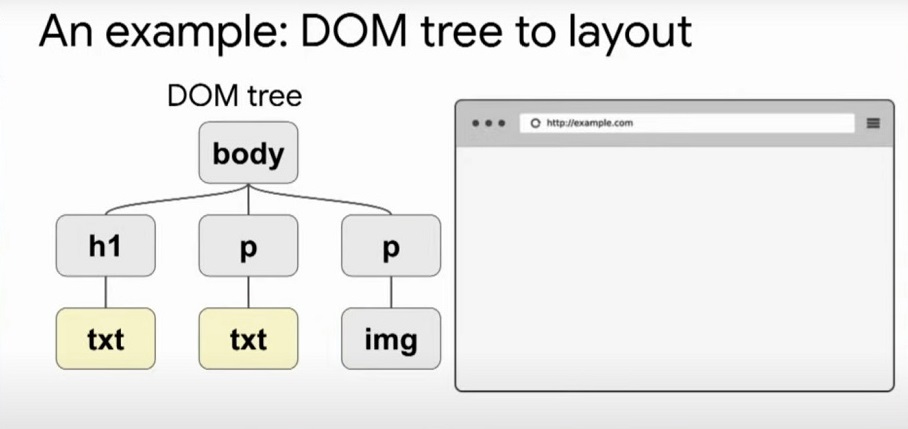
Based on the received HTML code, the application of rules from CSS and the execution of JS, the DOM - Document Object Model is formed. - Styles are loaded and recognized, CSSOM is formed - CSS Object Model.
- Based on the DOM and CSSOM, a render tree is formed - a set of rendering objects. The render tree duplicates the DOM structure, but it does not include invisible elements (for example, or elements with the display:none; style). Each line of text is represented in the render tree as a separate renderer. And each render object contains its corresponding DOM object (or block of text) and the style calculated for this object. Simply put, render tree describes the visual representation of the DOM.
- For each element of the render tree, the position on the page is calculated - layout occurs. Browsers use the flow method, in which in most cases one pass is enough to lay out all the elements (more passes are required for tables of passes).
- Finally, everything that is listed in the browser is rendered - painting.
Mechanics
Rendering, i.e. rendering of the page in Google, starts after crawling, but before indexing. The mechanics are quite simple: the crawler requests the page and all the resources needed to render it.

The data is then passed to Rendertron, a headless chrome page rendering solution built with Puppeteer. All data is processed there.

There are two important factors that affect rendering:
1. Google tries to cache all resources and does not respect HTTP caching rules. This is due to the fact that most webmasters create them thoughtlessly, forcing users to constantly download the same file, although it has not changed.
2. Google may not get all the additional resources, so it's worth reducing the number of requests required to render the page well.

As for JavaScript processing, Google explicitly states that performance is important to them, therefore:
- limit the consumption of processor resources;
- can interrupt the execution of scripts;
- and say that excessive CPU consumption negatively affects indexing.

How to check page rendering by search robots
The first method is Google Search Console
This tool helps webmasters get more organic traffic and gives an understanding of how search engines perceive page content.
For any of the site addresses that are in the Google index, you can view the crawled page:

After clicking on the right side of the screen, a window opens, where the HTML code of the page rendered by the bot is displayed. This is how the search robot processed the document.

Here you can copy the HTML code of the rendered page and paste it into any of the code editors. And then you can review the code for correctness, check the presence of all important semantic elements, location in the DOM tree, micro-markup, internal links, and the rest.
You can save the document as HTML and view it visually in any browser. But it is more reliable to read and check the code, because modern browsers are very smart and can often fix gross layout errors and close tags themselves.
The second method is if the site is not yours and there is no access to GSC
This method is necessary if we want to compare the rendering of our pages and those of a competitor, to check if they give the bot improved pages with text content, and the user - more functional versions.
Rich Snippets Testing Tool
The tool sends a request to the server like native Google bots. And the response you get will be the same as the response the search crawler gets.

A big advantage of the tool is the ability to choose the type of search bot between desktop and mobile. This is useful when sites use the Dynamic Serving mobile optimization method. That is, depending on the device that makes the request, the server returns a different HTML code. Comparing the code of one page between different agents can reveal that, for example, the desktop receives pages with text, and the mobile does not. Also, in practice, we came across cases where the microdata that the bots received was also different.
After the test is completed, click View Tested Page. And we get a window with the rendered HTML code of the page, already familiar to us from the Google Search Console interface.
Mobile Friendly Test
This is the name of the page adaptability testing tool. Unlike the previous tool, here you cannot select a bot that will make a call to the server.

Click View Tested Page again and get into the same window as in the previous tool.
What to pay attention to when checking the code?
Semantically important areas in content:
- the title of the page in the title tag;
- page descriptions in meta tags;
- correctness of links in link tags;
- schema.org microdata elements.
Visually invisible, but important layout elements:
- document titles in h tags;
- text descriptions;
- the number of elements presented on the page (for example, product cards in listings);
- image addresses in the src attributes of the img tag;
- correctness of anchors and addresses in links.
Semantic layout elements:
- article, section, nav, table tags and their contents are present;
- these tags are correctly placed in the HTML version of the document indexed by the bot.
Comparison of rendered code from different tools
Is it possible to be sure that the page is rendered by the search bot exactly as we see it in the tools? If we are talking about Google Search Console - more likely yes than no. And speaking of other tools, including Rich Snippets Testing Tools and Mobile-Friendly Test, they may not always provide correct information.
The fact is that rendering is a dynamic process. And the result that we get is the result of a specific response to a specific request at a specific point in time. Will it match what the search crawler will get when requesting the same resource in a different time period? Possibly, but not guaranteed.
For example, we compared the code stored in Google Search Console with the rendered code of the same page received from:
- GSC Live Test;
- Rich Snippets Testing Tool
- Mobile Friendly Test;
- Rendered Page Screaming Frog.
GSC vs GSC Live Test
In the code obtained from the GSC Live Test, there is a difference in the form of adding a slash at the end before closing tags. But the HTML that is stored in the console does not contain such slashes. Also, Livetest did not see the googleads script, which is in the GSC version of the page from the index. The quotation marks are also different. In the version from the index, they look like this: ', and in the version from LiveTest, like this: ".

GSC vs Rich Snippets Testing Tool
There are a couple of minor differences in the GSC code. For example, the presence of the googleads script, which is not in the code from Rich Snippets, as well as in the code from Livetest. But more significant differences were not found.

GSC vs Mobile Friendly Test
The Mobile-Friendly Test collected all the differences between the two previous tests. There is no script in it, plus slashes are written before closing tags and quotes are replaced.

GSC vs Screaming Frog Rendered Page
The Screaming Frog engine has better page rendering capabilities than Google - the differences are observed in whole blocks. For example, for a Google bot, this block was display:none and empty, but in the rendered version in Screaming Frog it is also display:block with inner blocks containing content.

What if all the tools don't work?
In reality, this is unlikely. But if such a force majeure happens, the main working tool always remains in our hands - a web browser. To check which HTML document the browser received, you need to select the page file in the dev panel in the network tab. And then in the Preview tab, visual differences between the received page and the page after all additional scripts are executed will be visible.

But the Response tab will be more interesting and priority for us. Here you can see and parse the HTML document that the browser received.

The arrow in the screenshot shows the Beautifier button, which will make the code easier to read. If the site does not have a separate Server Side Rendering for the bot, it is important that we see all content blocks and semantic elements in this document. Then, regardless of the rendering resources of search robots, we can be sure that the bot has exactly received everything we need.
As a result
In practice, we often encounter situations where specialists from in-house teams do not understand why the site is not growing. But the fact is that search robots simply do not see most of the content on these resources, which leads to big losses in the race for top positions in search results. For this reason, we recommend that you use GSC to check the rendering of pages of your resource, and Rich Snippets Testing Tools to check the pages of competitors.
In the case of our clients, we simply do not allow their site to not have the correct rendering configured. For example, when we started working with FlyArystan, their resource contained all language versions on the same URL and did not render them separately. This was fixed before the site was released. And we recommend everyone to check it in the early stages of launch.
A source: Promodo.ua