Почему SEO не работает: как проверить рендеринг страниц на сайте?
Author - Constantin Nacul
Практически все современные веб-сайты разрабатываются с ориентацией на пользователей и на возможности рендеринга в браузерах. Как правило, браузеры без проблем справляются даже со сложными задачами.
Но если мы говорим об органическом поиске, то тут все поисковые системы ранжируют веб-страницы как HTML-документы. И у поисковых ботов, в отличие от современных браузеров, возможности ограничены. Если не побеспокоиться о том, как поисковые роботы видят ваши страницы, то можно проиграть в гонке за топовые позиции в органическом поиске.
Как проверить рендеринг сайта и устранить ошибки, которые мешают ранжированию, — рассказываем дальше.
Что такое рендеринг страниц в SEO?
Рендеринг — это термин из веб-разработки. Он обозначает отрисовку кода веб-документа в интерактивную веб-страницу, которую вы в итоге и видите в своих браузерах. Фактически рендеринг — это процесс выполнения всех правил, прописанных в HTML-коде, JS-скриптах и CSS-стилях.
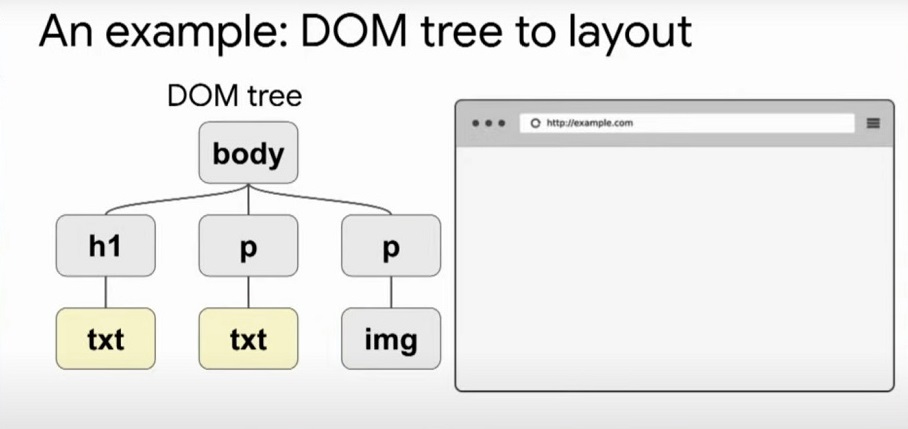
Что происходит в браузере при отображении документа:
- Браузер получает ресурсы с сервера (HTML-код, CSS, JS, картинок).
На основе полученного HTML-кода, применения правил из CSS и исполнения JS формируется DOM — Document Object Model. - Загружаются и распознаются стили, формируется CSSOM — CSS Object Model.
- На основе DOM и CSSOM формируется render tree — набор объектов рендеринга. Render tree дублирует структуру DOM, но сюда не попадают невидимые элементы (например,или элементы со стилем display:none;). Каждая строка текста представлена в дереве рендеринга как отдельный renderer. А каждый объект рендеринга содержит соответствующий ему объект DOM (или блок текста) и рассчитанный для этого объекта стиль. Проще говоря, render tree описывает визуальное представление DOM.
- Для каждого элемента render tree рассчитывается положение на странице — происходит layout. Браузеры используют поточный метод flow, при котором в большинстве случаев достаточно одного прохода для размещения всех элементов (для таблиц проходов требуется больше).
- Наконец, происходит отрисовка всего віше перечисленного в браузере — painting.
Механика
Рендеринг, то есть отрисовка страницы в Google, начинается после сканирования, но до индексации. Механика довольно простая: краулер запрашивает страницу и все ресурсы, необходимые для её отрисовки.

Далее данные передаются в Rendertron — headless chrome решение для рендеринга страниц, созданное с помощью Puppeteer. Там все данные обрабатываются.

Есть два важных фактора, которые влияют на рендеринг:
1. Google старается кэшировать все ресурсы и не учитывает правила HTTP-кэширования. Это связано с тем, что большинство вебмастеров создают их бездумно, заставляя пользователей постоянно скачивать один и тот же файл, хотя он не менялся.
2. Google может не получить все дополнительные ресурсы, поэтому стоит уменьшить количество запросов, необходимых для качественной отрисовки страницы.

Что касается обработки JavaScript, то в Google прямо заявляют — для них важна производительность, поэтому:
- ограничивают потребление ресурсов процессора;
- могут прерывать выполнение скриптов;
- и говорят о том, что чрезмерное потребление ресурсов ЦП негативно сказывается на индексации.

Как проверить рендеринг страниц поисковыми роботами
Первый метод — Google Search Console
Этот инструмент помогает вебмастерам получать больше трафика из органики и даёт понимание, как поисковые системы воспринимают контент страниц.
По любому из адресов сайта, который есть в индексе Google, можно просмотреть прокрауленную страницу:

После клика в правой части экрана открывается окно, где отображается отрендеренный ботом HTML-код страницы. Именно так поисковый робот и обработал документ.

Здесь можно скопировать HTML-код отрендеренной страницы и вставить в любой из редакторов кода. А дальше можно просмотреть код на корректность, проверить наличие всех важных семантических элементов, расположение в DOM-дереве, микроразметку, внутренние ссылки и остальное.
Можно сохранить документ как HTML и просмотреть в любом браузере визуально. Но надёжнее — читать и проверять код, потому что современные браузеры очень умные и часто могут сами исправлять грубые ошибки вёрстки и закрывать теги.
Второй метод — если сайт не ваш и доступов к GSC нет
Этот метод необходим, если мы хотим сравнить рендеринг своих страниц и страниц конкурента, проверить, не отдают ли они боту улучшенные страницы с текстовым контентом, а пользователю — более функциональные версии.
Rich Snippets Testing Tool
Инструмент направляет запрос к серверу как нативные Google-боты. И ответ, который вы получите, будет совпадать с ответом, который получает поисковый краулер.

Большое преимущество инструмента — возможность выбрать тип поискового бота между десктопом и мобайлом. Это полезно, когда на сайтах используется метод оптимизации для мобильных устройств Dynamic Serving. То есть, в зависимости от устройства, которое делает запрос, сервер отдаёт разный HTML-код. Сравнение кода одной страницы между разными агентами может выявить, что, например, десктоп получает страницы с текстом, а мобайл — без. Также на практике мы сталкивались со случаями, когда отличалась и микроразметка, которую получали боты.
После завершения теста нажимаем View Tested Page. И получаем окно с отрендеренным HTML-кодом страницы, уже знакомое нам из интерфейса Google Search Console.
Mobile-Friendly Test
Так называется инструмент тестирования адаптивности страниц. В отличие от предыдущего инструмента, здесь нельзя выбрать бота, который будет делать обращение к серверу.

Снова нажимаем View Tested Page и попадаем в то же окно, что и в предыдущем инструменте.
На что обратить внимание при проверке кода?
Семантически важные зоны в контенте:
- название страницы в теге title;
- описания страниц в тегах meta;
- корректность ссылок в тегах link;
- элементы микроразметки schema.org.
Визуально неотображаемые, но важные элементы вёрстки:
- заголовки документа в тегах h;
- текстовые описания;
- количество представленных элементов на странице (например, карточек товаров в листингах);
- адреса изображений в атрибутах src тега img;
- корректность анкоров и адресов в ссылках.
Семантические элементы верстки:
- теги article, section, nav, table и их содержимое присутствуют;
- эти теги корректно размещены в HTML-версии документа, которую проиндексировал бот.
Сравнение отрендеренного кода из разных инструментов
Можно ли быть уверенным, что страница рендерится поисковым ботом именно так, как мы видим в инструментах? Если речь идёт о Google Search Console — скорее да, чем нет. А если говорить о других инструментах, в том числе Rich Snippets Testing Tools и Mobile-Friendly Test, — они могут не всегда отдавать корректную информацию.
Дело в том, что рендеринг — это динамический процесс. И результат, который мы получаем, — это результат конкретного ответа на конкретный запрос в конкретный момент времени. Совпадёт ли он с тем, что получит поисковый краулер при запросе к тому же ресурсу в другой промежуток времени? Возможно, но не гарантированно.
Для примера мы сравнили код, который хранится в Google Search Console, с полученным отрендеренным кодом той же страницы из:
- GSC Live Test;
- Rich Snippets Testing Tool;
- Mobile-Friendly Test;
- Rendered Page Screaming Frog.
GSC vs GSC Live Test
В коде, полученном из GSC Live Test, есть отличия в виде добавления слеша в конце перед закрытием тегов. Но HTML, который хранится в консоли, не содержит таких слешей. Также Livetest не увидел скрипта googleads, который есть в GSC-версии страницы из индекса. Отличаются и кавычки. В версии из индекса они выглядят так: ‘, а в версии из LiveTest вот так: «.

GSC vs Rich Snippets Testing Tool
В коде GSC есть пара несущественных отличий. Например, присутствие скрипта googleads, которого нет в коде из Rich Snippets, как и в коде из Livetest. Но более существенных различий не обнаружено.

GSC vs Mobile-Friendly Test
Mobile-Friendly Test собрал все различия двух предыдущих тестов. В нём нет скрипта, плюс перед закрытием тегов записываются слеши и подменяются кавычки.

GSC vs Screaming Frog Rendered Page
У движка Screaming Frog возможности по рендерингу страниц лучше, чем в Google — отличия наблюдаются в целых блоках. Например, для Google-бота данный блок был display:none и пустой, а в отрендеренной версии в Screaming Frog он же display:block с внутренними блоками, в которых есть контент.

Что делать, если все инструменты не работают?
В действительности это маловероятно. Но если такой форс-мажор и случится, в наших руках всегда остаётся основной рабочий инструмент — веб-браузер. Чтобы проверить, какой HTML-документ получил браузер, нужно выбрать файл страницы в dev-панели во вкладке network. А дальше во вкладке Preview будут видны визуальные отличия между полученной страницей и страницей после выполнения всех дополнительных скриптов.

Но более интересной и приоритетной для нас будет вкладка Response. Здесь можно увидеть и разобрать HTML-документ, который получил браузер.

Стрелкой на скриншоте показана кнопка Beautifier, которая упростит чтение кода. Если на сайте нет отдельного Server Side Rendering для бота, важно, чтобы в этом документе мы видели все контентные блоки и семантические элементы. Тогда, независимо от ресурсов рендеринга у поисковых роботов, можно быть уверенным, что бот точно получил всё, что нам нужно.
Как итог
На практике мы часто сталкиваемся с ситуациями, когда специалисты из инхаус-команд не понимают, почему сайт не растёт. А дело в том, что поисковые роботы просто не видят большей части контента на этих ресурсах, — что приводит к большим потерям в гонке за топовые позиции в поисковой выдаче. По этой причине рекомендуем использовать для проверки рендеринга страниц своего ресурса GSC, а для проверки страниц конкурентов — Rich Snippets Testing Tools.
В случае с нашими клиентами мы просто не допускаем, чтобы на их сайте не был настроен корректный рендеринг. Например, когда мы начали работу с FlyArystan, их ресурс содержал все языковые версии на одном URL и не рендерил их отдельно. Исправили это ещё до релиза сайта. И всем рекомендуем проверять это на ранних этапах запуска.
Источник: Promodo.ua